

AI transcription is no longer just a futuristic productivity feature. In 2026, speech to text software has become part of everyday workflows for businesses, students, creators, healthcare professionals, and remote teams.
People now use AI transcription software for meetings, lecture notes, interviews, podcasts, customer calls, and quick idea capture because modern speech recognition systems are dramatically faster and more practical than older dictation tools.
At the same time, there is still a major gap between marketing claims and real-world performance.
Many AI transcription platforms advertise extremely high accuracy numbers, but transcription quality depends heavily on audio conditions.
Clean single-speaker recordings may produce near-perfect transcripts, while noisy meetings with overlapping conversations can still challenge even the best speech recognition software.
That is the real benchmark story in 2026.
This article explains how AI transcription accuracy is measured, what Word Error Rate (WER) actually means, how modern speech-to-text software performs in real-world environments, and why some audio remains much harder for AI systems to transcribe accurately than others.
What Is AI Transcription?
AI transcription is the process of converting spoken language into written text using speech recognition and artificial intelligence technologies.
Modern AI transcription software uses automatic speech recognition (ASR), machine learning, and natural language processing (NLP) to understand spoken conversations more accurately than traditional dictation systems.
Unlike older voice recognition tools that struggled with natural conversation, today’s AI transcription software is designed for real-world speech.
These systems can process meetings, lectures, interviews, podcasts, and conversational audio much more effectively because modern AI models understand language context instead of analyzing words in isolation.
This is one reason speech-to-text software has become so valuable across productivity workflows.
Businesses use AI transcription for meeting documentation, students use it for lecture notes, healthcare professionals use it for medical dictation, and creators use it for interviews, subtitles, and content production.
For many users, the biggest advantage is speed. Speaking naturally is often much faster than typing everything manually, especially during live conversations or brainstorming sessions.
What Is Word Error Rate (WER)?
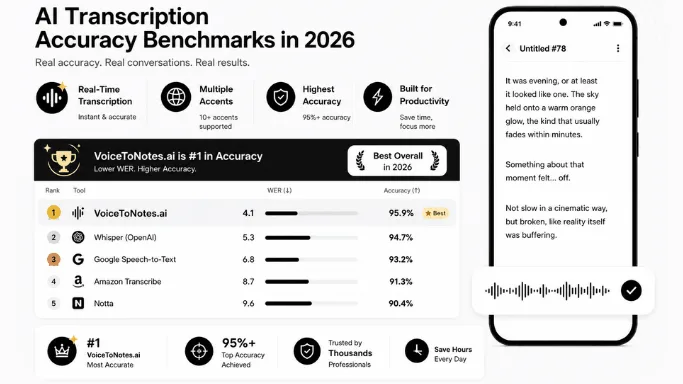
Word Error Rate (WER) is the standard benchmark used to measure AI transcription accuracy by comparing AI-generated transcripts against human reference transcripts.
WER measures how many words inside a transcript were incorrect. The benchmark is widely used across speech recognition research because it provides a simple way to compare transcription quality between different AI systems.
The formula looks like this:
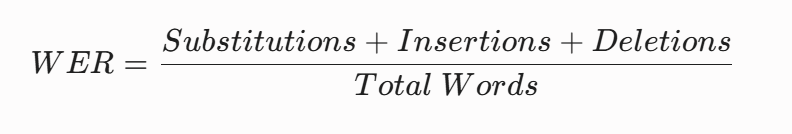
WER=Total WordsSubstitutions+Insertions+Deletions
In simple terms:
- substitutions happen when the AI hears the wrong word
- insertions happen when extra words appear that were never spoken
- deletions happen when words are missed entirely
Lower WER means better transcription accuracy.
A transcript with 5% WER may need only minor edits, while a transcript with 15% or 20% WER can create significantly more cleanup work. Even small differences in error rate become noticeable during long meetings or detailed documentation workflows.
However, Word Error Rate is not the full story.
A transcript can score well on WER while still struggling with:
- speaker labels
- punctuation
- formatting
- names and proper nouns
- readability
- overlapping speech
That distinction matters because real-world transcription quality is not just about reducing errors. It is about generating text that people can actually use without spending excessive time editing.
AI Transcription Accuracy in 2026: The Real Benchmark Picture
The biggest change in recent years is not that AI transcription became perfect. It is that speech recognition software became consistently useful across many more real-world situations.
In clean audio environments, modern AI transcription software performs remarkably well. But once conversations become messy, fast, noisy, or multi-speaker, accuracy can still decline quickly.
That balance is important to understand because most real-world conversations are far less controlled than benchmark datasets.
Clean Audio Performance Is Better Than Ever
Modern AI speech recognition systems perform best when audio is clean and structured. Single-speaker recordings with clear microphones and minimal background noise can now produce highly accurate transcripts suitable for professional workflows.
This includes scenarios like:
- voice notes
- webinars
- podcasts
- dictation
- lecture recordings
- solo presentations
In these situations, speech to text software often feels surprisingly reliable. Many users now trust AI transcription tools for daily productivity because transcription quality is good enough to save meaningful amounts of time.
For students, this means searchable lecture notes without constant typing. For creators, it means faster podcast transcription and content repurposing. For professionals, it means faster documentation and meeting summaries.
The gap between manual transcription and AI transcription has narrowed dramatically for clean audio workflows.
Meeting Transcription Is Still One of the Hardest Challenges
Meetings remain one of the most difficult environments for AI transcription software.
At first glance, meetings may seem simple to transcribe. In practice, they introduce several challenges at the same time. People interrupt each other, microphones vary in quality, speakers change constantly, and conversations often include jargon, incomplete sentences, or overlapping speech.
Even when a transcript looks “mostly correct,” problems with speaker attribution and conversational flow can make the final output harder to use.
This is why meeting transcription software should never be judged only by marketing accuracy claims. Real-world meeting transcription depends heavily on:
- microphone placement
- room acoustics
- speaker overlap
- speaking clarity
- background noise
- participant behavior
Modern AI meeting assistants are much better than earlier speech recognition systems, but group conversations continue to push the limits of real-time transcription accuracy.
For most businesses, the practical question is no longer “Can AI transcribe meetings?” The more important question is how much editing is still required afterward.
Why Audio Quality Still Matters So Much
One of the biggest misconceptions around AI transcription is that modern systems can fully ignore poor audio quality.
That is not true.
Speech recognition software has become far more noise-resistant than it was a few years ago, but audio quality still has a major impact on transcription performance. Background conversations, weak microphones, echo-heavy rooms, laptop fan noise, and poor internet calls can still increase transcription errors significantly.
The difference becomes especially obvious during long meetings or recordings with multiple speakers.
In quiet environments, modern AI transcription software can feel almost seamless. In noisy or chaotic environments, even advanced systems may struggle with conversational clarity and speaker separation.
For businesses and professionals using speech-to-text software daily, investing in better microphones often improves transcription quality more than switching between transcription platforms.
Accent Recognition Has Improved, But It Is Not Perfect
Accent support is another area where AI transcription software has improved substantially.
Modern AI speech recognition systems now handle a much wider variety of speaking styles, dialects, and conversational rhythms than older ASR systems. This improvement comes largely from larger training datasets and better transformer-based language models.
However, accuracy is still not perfectly balanced across all accents and recording conditions.
Strong accents combined with:
- poor microphones
- noisy environments
- overlapping conversations
- inconsistent audio
can still create transcription challenges.
This is why businesses evaluating AI transcription software should test tools using real recordings from their own workflows instead of relying only on benchmark claims or demo videos.
Real-world transcription accuracy depends heavily on the type of audio being processed.
Why AI Transcription Improved So Much
The improvement in AI transcription accuracy over the last few years came from several major technological advances happening at the same time.
One of the biggest shifts was the adoption of transformer-based AI models. Older speech recognition systems processed words more narrowly and struggled with conversational context. Modern AI models understand language relationships much more effectively, allowing systems to interpret speech more naturally across longer conversations.
Training data also became dramatically larger and more diverse. Earlier ASR systems learned mostly from carefully recorded speech datasets. Modern AI transcription systems learn from podcasts, meetings, interviews, phone calls, lectures, and noisy real-world conversations. This broader exposure helps speech recognition software perform better across different environments and speaking styles.
Natural Language Processing also plays a major role in modern AI transcription accuracy. NLP helps systems understand sentence structure, conversational context, and likely word relationships. This is why many modern transcription platforms can now generate:
- summaries
- timestamps
- organized notes
- speaker separation
- action items
instead of producing only raw text.
The result is that AI transcription software feels much more intelligent and usable than earlier dictation systems.
Why WER Is Not the Only Metric That Matters
Many buyers focus too heavily on Word Error Rate when comparing AI transcription software.
WER is important, but it does not measure the full user experience.
A transcript can technically score well while still being frustrating to read because of:
- poor punctuation
- weak formatting
- missing speaker labels
- confusing timestamps
- inconsistent readability
For real-world productivity workflows, usability matters just as much as benchmark performance.
A transcript that requires heavy cleanup still creates friction even if its technical error rate looks impressive.
This is why many businesses now evaluate transcription software based not only on speech recognition accuracy, but also on how easily transcripts fit into daily workflows.
Searchability, organization, readability, and collaboration features often matter just as much as raw AI speech recognition benchmarks.
What These Benchmarks Mean for Everyday Users
For many users, AI transcription software is already more than accurate enough for practical daily use.
Students use speech-to-text software for lecture notes and study summaries. Businesses rely on AI transcription tools for meetings and documentation. Healthcare professionals use medical dictation software to reduce charting time. Content creators use AI transcription for interviews, subtitles, and production workflows.
The real value is no longer simply “Can AI transcribe speech?”
The bigger value is:
- saving time
- reducing manual typing
- capturing ideas quickly
- creating searchable notes
- improving workflow efficiency
That is the shift happening in 2026.
AI transcription has moved beyond novelty and become a genuine productivity tool.
AI Transcription vs Manual Typing
Manual typing still works better for tasks requiring:
- detailed editing
- formatting precision
- coding
- structured writing
But AI transcription software is dramatically faster for:
- idea capture
- meetings
- brainstorming
- voice notes
- lecture transcription
- rough drafting
Most professionals now combine speech-to-text software with manual editing inside hybrid workflows.
Instead of replacing typing completely, AI transcription is becoming part of a faster productivity system where speaking captures ideas quickly and editing refines them afterward.
The Future of AI Transcription
AI transcription software is evolving beyond simple speech-to-text conversion.
Modern transcription platforms increasingly combine:
- AI speech recognition
- NLP
- conversational AI
- searchable knowledge systems
- meeting intelligence
Future systems will likely become:
- more context-aware
- stronger with accents
- better at multi-speaker conversations
- more personalized
- more integrated into productivity workflows
This is one reason AI transcription is becoming a major technology category rather than just a small productivity feature.
The long-term shift is not simply toward transcription accuracy. It is toward AI systems that help people organize, search, understand, and use spoken information more effectively.
FAQs
How accurate is AI transcription in 2026?
Modern AI transcription software is highly accurate for clean single-speaker audio and significantly better than older speech recognition systems. Accuracy can decline in noisy meetings or overlapping conversations.
What is considered a good Word Error Rate?
In many workflows, under 10% WER is considered strong. Around 5% WER often feels highly accurate and requires minimal editing.
Is AI transcription accurate enough for meetings?
AI meeting transcription has improved significantly, but meetings remain challenging because of multiple speakers, interruptions, and overlapping speech.
Does AI transcription work well with accents?
Modern speech recognition software supports many accents better than older systems, although performance still depends on recording quality and conversational conditions.
Why do transcription results vary so much?
AI transcription accuracy depends heavily on microphone quality, audio clarity, background noise, speaker overlap, and speaking style.
Is Word Error Rate the only transcription benchmark that matters?
No. Real-world transcription quality also depends on readability, punctuation, formatting, speaker labels, timestamps, and usability.
What type of audio gives the best transcription results?
Clear single-speaker audio with minimal background noise and good microphone quality usually produces the best AI transcription accuracy.
Can AI transcription replace manual typing completely?
For meetings, lecture notes, brainstorming, and idea capture, AI transcription software can save significant time. Manual typing is still better for detailed editing and formatting tasks.
Final Verdict
AI transcription accuracy in 2026 is genuinely impressive, especially for clean single-speaker audio and structured conversations. Modern speech recognition software is now reliable enough for many professional workflows, including meetings, lecture notes, documentation, and content creation.
At the same time, transcription quality still depends heavily on audio conditions. Background noise, speaker overlap, accents, microphone quality, and conversational complexity continue to affect performance in real-world environments.
That does not make AI transcription unreliable. It simply means users should have realistic expectations about how speech-to-text software performs across different types of audio.
For most users, the biggest advantage is no longer raw accuracy alone. It is how quickly conversations become searchable, editable, and usable information without hours of manual typing.
That is why AI transcription software is becoming a core productivity tool across education, healthcare, business, and content creation workflows in 2026.
Disclosure: VoiceToNotes is developed by our team and is included in this comparison. To maintain fairness, every product is evaluated using the same review criteria.

.webp)

.webp)